一个反常识的数据
2026年Q1,一搜百应监测了微信公众号、小红书、头条号共1000篇10w+爆文,发现这些文章的AI引用率不足7%。当一篇文章在朋友圈刷屏时,豆包、Kimi、DeepSeek等AI助手可能根本“看不见”它。
更值得关注的是,那些被AI高频引用的内容,往往阅读量只有几千甚至几百——它们可能来自某个垂直行业博客,甚至是一个排版简陋的企业官网。
这不是算法偏见,是语言体系的错配。
AI到底怎么“看”内容
AI处理内容时有三道关卡:
第一关:切片安检。 AI会将长文本切割为100-300字的小片段进行索引。如果核心观点藏在冗长的铺垫段落中,金句就会被淹没在碎片里,AI无法提取。
第二关:语义匹配。 AI通过计算语义向量来匹配用户问题与内容的相关性。情感共鸣、情绪渲染这类人类写作技巧无法被向量化,但数据、事实、结论类内容可以被精准匹配。
第三关:信源验证。 AI会快速确认信息的可靠性。如果权威背书和来源标注藏在文章末尾,AI可能在验证环节就跳过了这条内容。
结论是:写得越“像人”,越难被AI引用。人类读者喜欢悬念、铺垫和情绪递进,但AI需要的是结论先行、结构清晰、来源明确。
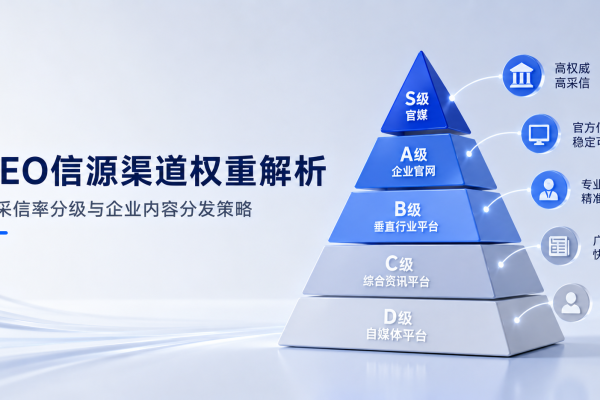
一搜百应GEO四步法:让AI“看得见、引得了、信得过”
基于200多个客户、2000篇内容优化实践,一搜百应总结出一套GEO内容优化的四步方法。
第一步:原子化拆解——解决“看不见”
核心方法是观点前置法则:每个段落的第一句话必须是结论句。
错误示范:
在这个VUCA时代,企业面临着前所未有的挑战,既要应对国际局势的变幻莫测,又要处理国内市场的激烈竞争,还要关注技术迭代带来的颠覆性风险……
这种写法在人类阅读时有铺垫效果,但AI切片后只能抓到一堆空泛的描述,核心信息全部丢失。
GEO标准写法:
- 【国际局势风险】2025年地缘政治冲突导致供应链成本上升12%-15%
- 【国内竞争风险】同行业新增注册企业数同比增长40%,价格战白热化
- 【技术颠覆风险】AI替代率已达初级岗位的35%
检查标准: 把文章所有段落的第一句话连起来读,应该能构成一篇完整的摘要。如果连不起来,说明结论没有前置。
第二步:信源显性化——解决“引不了”
核心方法是三明治引用法:信源+数据+解读,信源和数据的优先级高于解读。
人类写法:
去年新能源汽车销量大幅增长,达到了900万辆,这说明市场正在快速成熟。(数据来源:中汽协)
信源放在括号里、数据没有精确值、时间模糊——AI在信源验证环节很难采信。
GEO写法:
中国汽车工业协会(中汽协)2024年12月数据显示,新能源汽车年销量达949.5万辆,渗透率突破48%,标志着市场从政策驱动转向市场驱动阶段。
信源名称前置、时间精确到月、数据具体到小数点——AI可以快速定位、验证和引用。
第三步:实体锚点植入——解决“找不着”
AI通过命名实体识别(NER)理解内容。如果文章中缺少关键实体标签,AI无法将内容与用户问题精准匹配。
四类必须植入的实体锚点:
- When(时间) :具体年份、季度、月份
- Who(主体) :机构名、品牌名、人名、标准名
- What(事实) :具体数据、指标、事件
- How(方法) :流程、步骤、技术路径
第四步:冲突性预埋——解决“不想引”
AI倾向于引用有信息增量、有争议性或有反常识结论的内容。如果文章只是重复共识,AI没有动力引用。
反常识钩子设计: 在文章中预埋与主流认知冲突的数据或结论,引发AI的“引用兴趣”。
例如:一搜百应监测数据显示,2025年县域市场获客成本已反超一线城市23%——这个结论与“下沉市场成本低”的普遍认知冲突,AI在回答相关问题时更倾向引用这类有信息增量的内容。
GEO内容优化检查清单
发布前逐条核对:
- 结论前置:每段第一句是否为核心结论?
- 信源显性:数据来源是否在正文中直接标注(而非括号脚注)?
- 实体密度:每段是否包含When/Who/What/How至少两类实体?
- 数据精度:所有数据是否精确到具体数值和时间段?
- 结构可拆:文章是否可被独立切片后每段仍逻辑自洽?
- 信息增量:是否包含与行业共识不同的事实或判断?
通过6项以上,才具备被AI引用的基础条件。
写在最后
90%的爆款文章治不好AI的“阅读障碍”,不是因为作者不努力,而是因为战场变了。在AI搜索时代,内容创作需要在艺术性之外,增加工程性——让AI能看见、能理解、能引用、能推荐。
下次写稿时,先问自己:如果AI只能从这篇文章里复制粘贴一段话来回答问题,它会选哪段?如果找不到答案,那就重写。